@misc{zhao2025d1scalingreasoningdiffusion,
title={d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning},
author={Siyan Zhao and Devaansh Gupta and Qinqing Zheng and Aditya Grover},
year={2025},
eprint={2504.12216},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2504.12216}
}
Abstract
Scaling Reasoning in Diffusion LLMs via RL
Recent large language models (LLMs) have demonstrated strong reasoning capabilities that benefit from online reinforcement learning (RL). These capabilities have primarily been demonstrated within the left-to-right autoregressive (AR) generation paradigm. In contrast, non-autoregressive paradigms based on diffusion generate text in a coarse-to-fine manner. Although recent diffusion-based large language models (dLLMs) have achieved competitive language modeling performance compared to their AR counterparts, it remains unclear if dLLMs can also leverage recent advances in LLM reasoning.
To this end, we propose d1, a framework to adapt pre-trained masked dLLMs into reasoning models via a combination of supervised finetuning (SFT) and RL. Specifically, we develop and extend techniques to improve reasoning in pretrained dLLMs: (a) we utilize a masked SFT technique to distill knowledge and instill self-improvement behavior directly from existing datasets, and (b) we introduce a novel critic-free, policy-gradient based RL algorithm called diffu-GRPO.
Improved Reasoning in Math and Logical Tasks
Through empirical studies on multiple mathematical and logical reasoning benchmarks, we find that d1 yields the best performance and significantly improves the capabilities of state-of-the-art dLLMs.
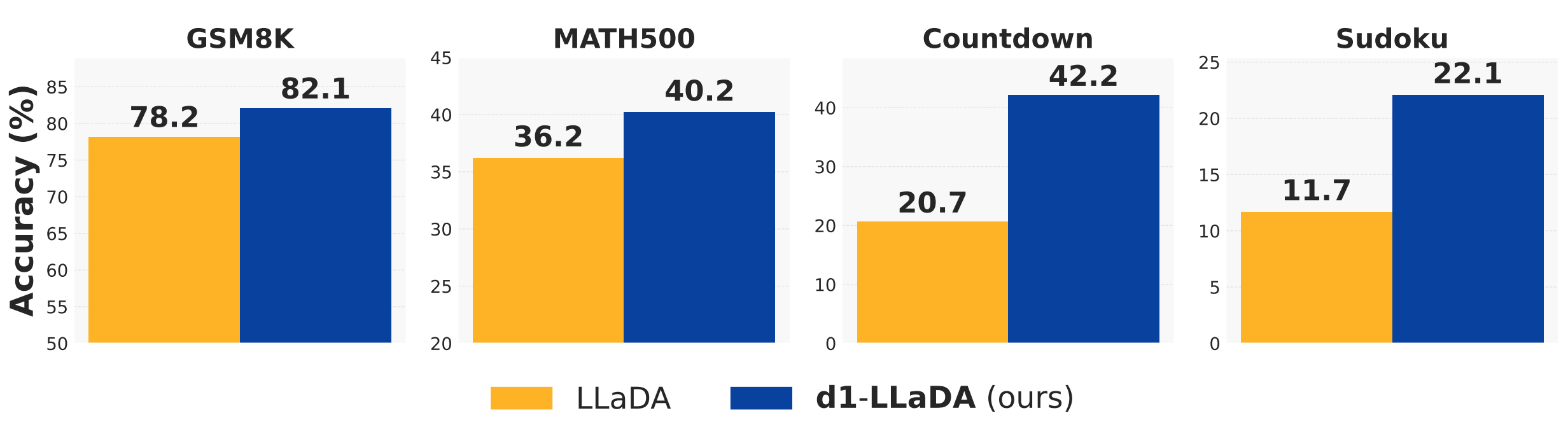
Across four math and logical reasoning tasks, d1-LLaDA, which undergoes SFT followed by our proposed diffu-GRPO, consistently outperforms the base LLaDA-8B-Instruct model.
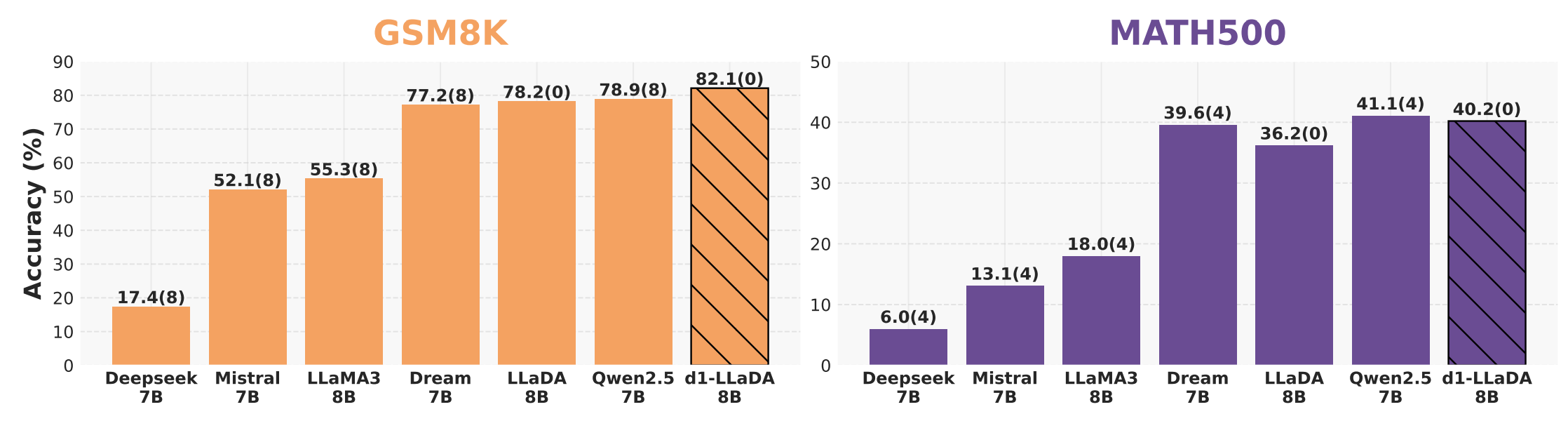
d1-LLaDA achieves the highest GSM8K score and competitive MATH500 performance compared to recent leading dLLMs and similar-sized AR LLMs.
Methodology
d1: Two-Stage Framework to Enhance Reasoning in Masked dLLMs
Stage 1: Masked SFT on High-Quality Reasoning Traces

We perform SFT on s1k, a curated dataset consisting of 1000 high-quality reasoning questions. The reasoning traces exhibit detailed step-by-step problem-solving processes, including verification of intermediate results and backtracking when encountering errors.
Stage 2: Efficient Policy Gradient Algorithm for dLLMs - diffu-GRPO
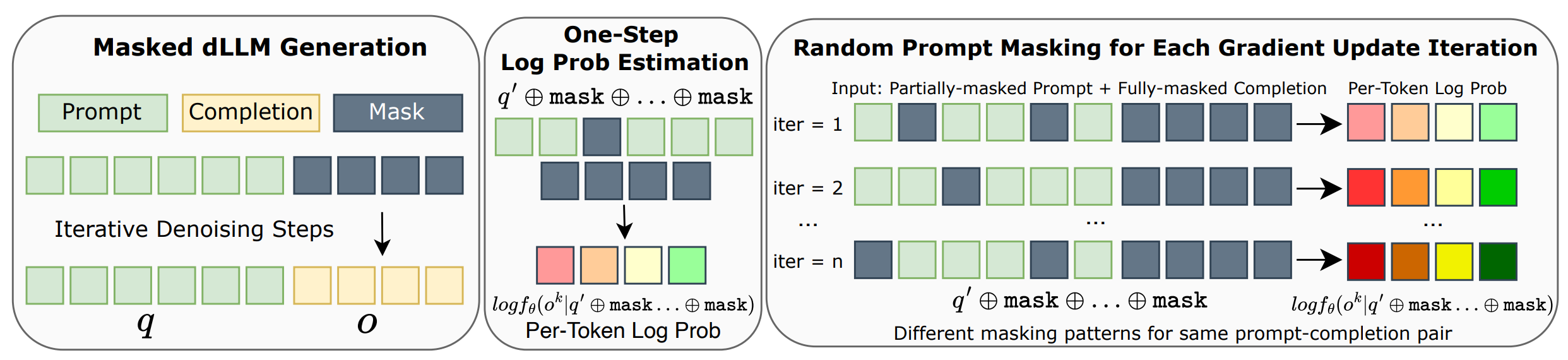
Estimating log-probabilities in dLLMs requires innovative approaches since they lack the natural sequential factorization of autoregressive models.
Adapting RL algorithms to masked dLLMs poses unique challenges since existing approaches for AR models (PPO and GRPO) rely on computing log-probabilities of generated sequences, which cannot be directly applied to dLLMs. While AR models use sequential factorization, dLLMs lack this natural decomposition due to their iterative, non-sequential generation process.
To address this, we propose an efficient log-probability estimator using Mean-Field Approximation of Sequence Log Probability. This approach decomposes sequence-level log-probability with a simple mean-field decomposition and employs One-Step Per-Token Log Probability Estimation with Prompt Masking.
Using this estimator, we extend GRPO to masked dLLMs with the following objective:
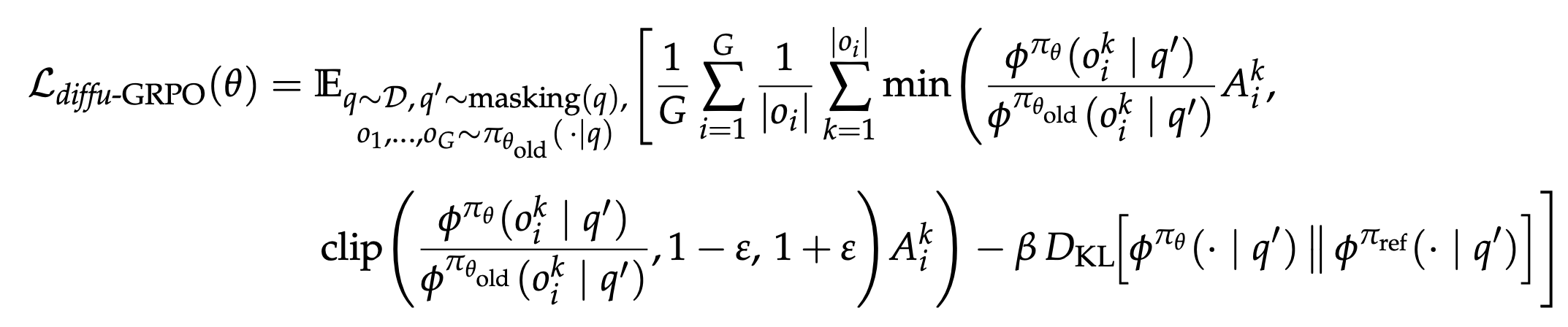
The diffu-GRPO objective builds on GRPO while leveraging our efficient log-probability estimators.
On-policy RL algorithms typically perform multiple gradient updates per batch of samples, requiring a careful balance between outer batch iterations and inner gradient updates. Our log-probability estimator introduces stochastic masking that creates perturbed views of the same (prompt, completion) pairs, serving as regularization for policy optimization. This unique approach allows us to scale the number of inner updates (μ) to higher values while maintaining stable learning dynamics, reducing the number of outer batch iterations and online generations needed—ultimately lowering computational cost significantly.

Efficiency Analysis
Benefits of Random Masking
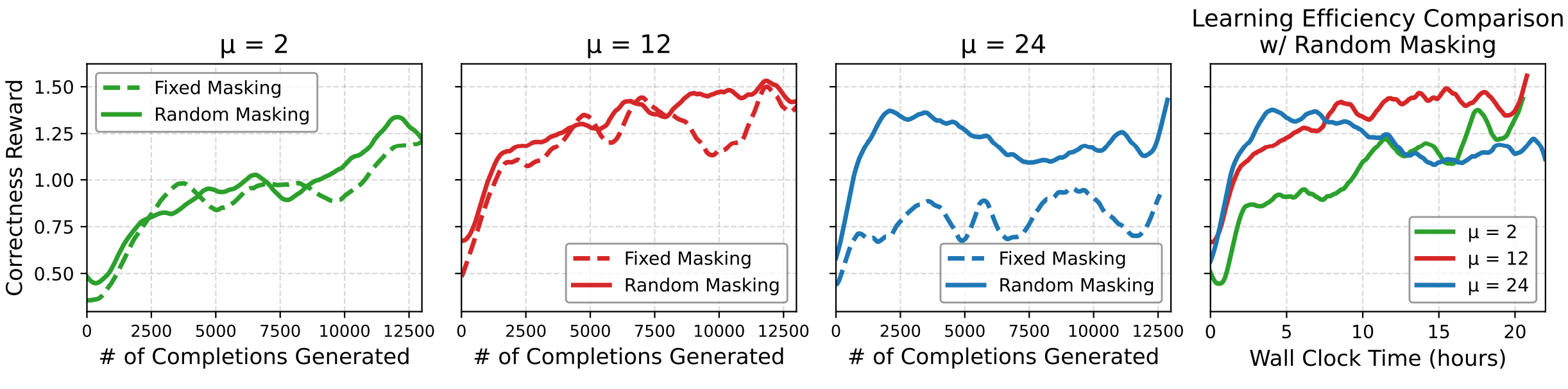
Random masking consistently outperforms fixed masking and allows scaling μ (gradient updates per batch) to much higher values while maintaining or improving performance, facilitating faster convergence of RL training.
Benchmark Results
Detailed Performance Results
Table below shows the detailed performance comparison across different benchmarks and generation sequence lengths. d1-LLaDA consistently outperforms all other models, with diffu-GRPO showing better performance than SFT alone.
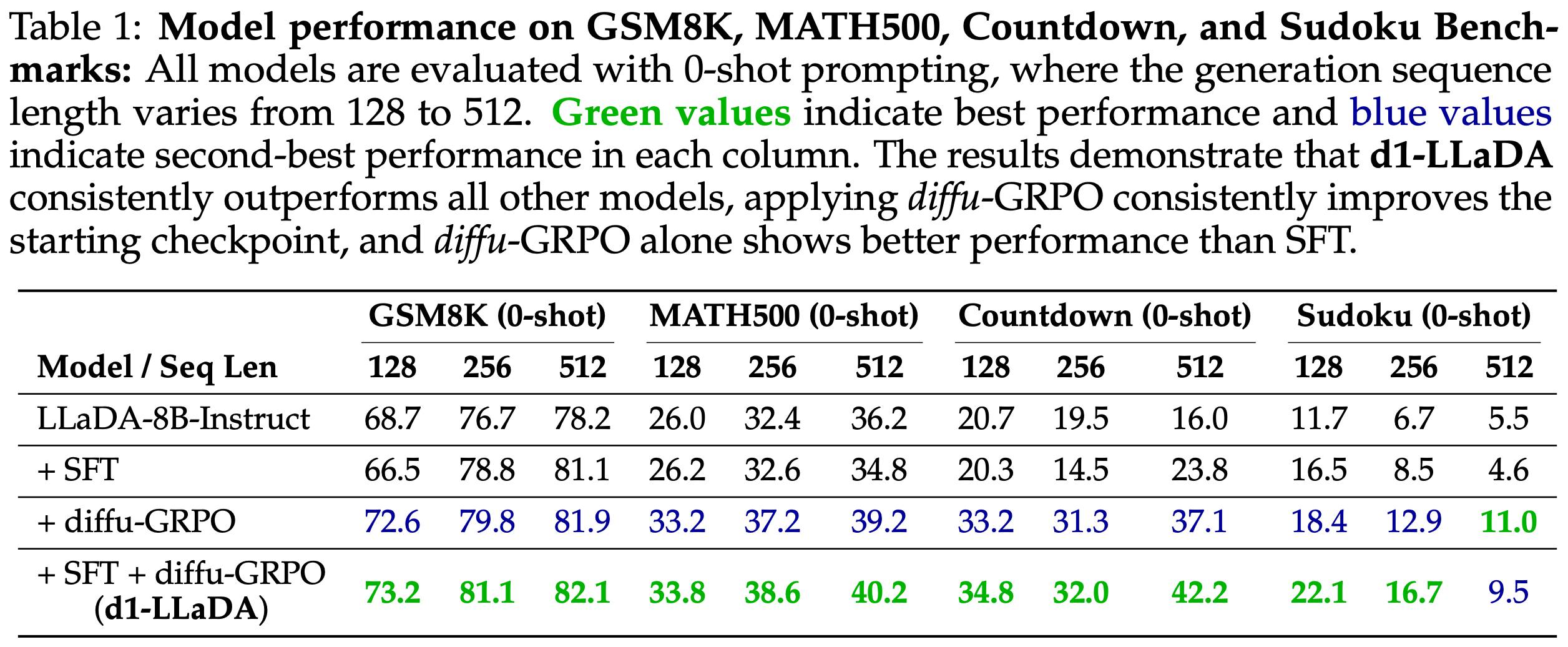
Table: Model performance on GSM8K, MATH500, Countdown, and Sudoku benchmarks. Green values indicate best performance and blue values indicate second-best performance in each column. All models are evaluated with 0-shot prompting.
Qualitative Analysis
"Aha Moments" in Reasoning

SFT and d1-LLaDA models show self-verification and self-correction behaviors ("aha moments") in their reasoning traces.
The models trained with SFT show self-verification and self-correction behaviors in their reasoning traces, where they can recognize errors in their initial reasoning paths, backtrack, and correct to arrive at the answer.